正则表达式的学习笔记
正则表达式(Regex)是学习爬虫所不能不逾越的一座大山,既然下定决心要学爬虫,那就认真来学一学正则表达式吧!
在开始之前,推荐一个学习正则表达式的网站
大家可以从这个网站中在线测试正则表达式的匹配情况,边学习边实践,事半功倍哦~
首先,什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。一个正则表达式是一种从左到右匹配主体字符串的模式,常使用缩写的术语“regex”或“regexp”。
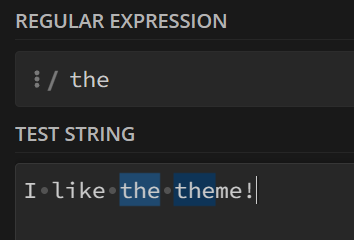
一、最简单的字符串匹配
匹配给定的字符串
但是,如果想要匹配的对象不巧是元字符怎么办?
好办!
使用转义字符\即可。
例如,想要匹配字符串中的所有句号.
则这样写:
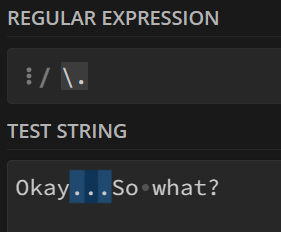
实际上这被称为转码特殊字符
二、元字符
正则表达式主要依赖于元字符。元字符不代表他们本身的字面意思,他们都有特殊的含义。一些元字符写在方括号中的时候有一些特殊的意思。以下是一些元字符的介绍:
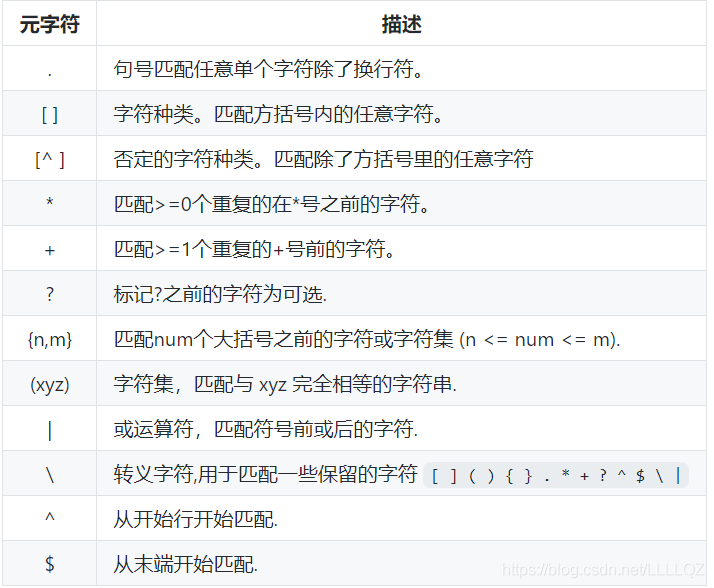
下面,我们逐个来理解熟悉:
注:在介绍元字符时,编者使用字符 c作为示例字符,便于进行用法说明。
1. 句号 .
匹配所有后缀为c的单个字符
举例:
若表达式为
.ar,则是匹配后缀为ar的字符
若表达式为.e,则是匹配后缀为e的字符串
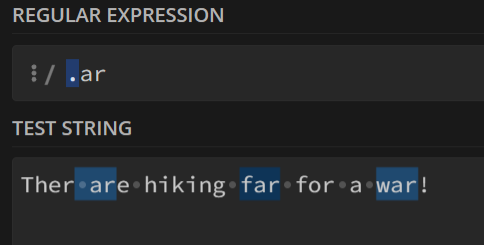
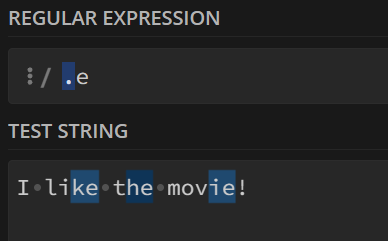
只能匹配该后缀以及其前面的一个字符!
2. 字符集 []
匹配字符集内任意一个字符以及后面相连的字符串
举例:
若表达式为
[Tt]he,则会匹配字符串中的所有The和the
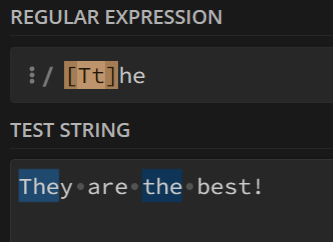
字符集中的字符没有顺序之分!
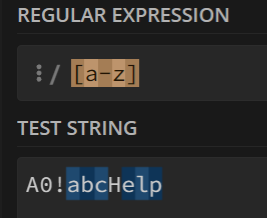
此外,在字符集中,有诸如a-z,A-Z,0-9的特殊用法,分别表示小写字母、大写字母、数字。
3. 否定字符集
字符^在[]使用,表示否定含义。
例如:
[^a]re,则代表匹配所有以re结尾,但是re前面不是a的字符串
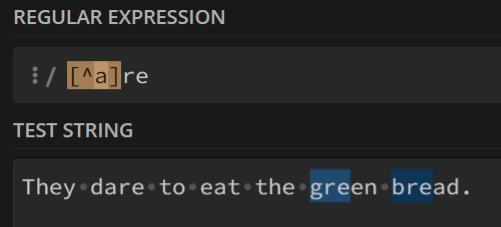
注意:只有当^位于字符集开头时,才会代表否定含义!
4. *号
c*表达式将会统计字符串中出现≥0次的c
即统计空字符和任意数量的c
例如:
若表达式为
a*,则会去匹配字符串中连续出现≥0次的a,即’’,’a’,’aa’,’aaa’,’aaaa’…..
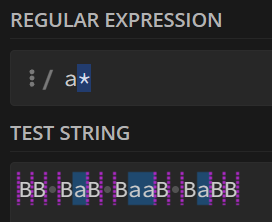
可以看到,所有的空字符、连续出现的a都被统计了
5. +号
与c*号类似,不过变成了连续出现≥1次
即统计所有的任意数量的c
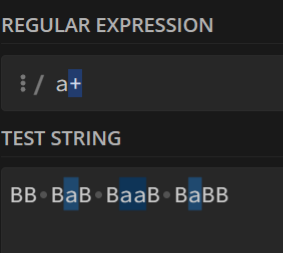
在前面几个的基础上,我们就可以形成组合拳!
例如:
挑出结尾是≥1个连续的
t的字符串就可以这样写:
可以对比一下不加
+的效果:
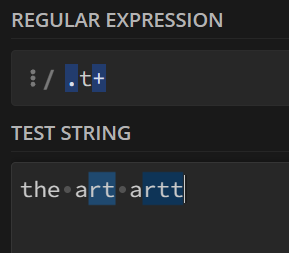
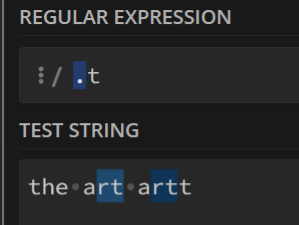
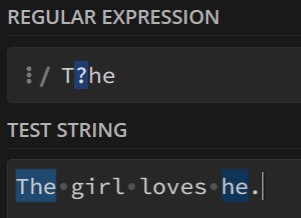
6. ?号
?号前面的字符可出现,也可不出现
例如:
T?he会匹配所有的The和he,因为T可出现可不出现
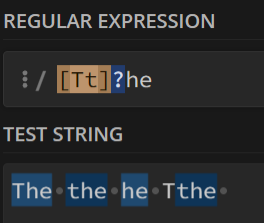
当然,我们大可以做一套组合拳,就像这样:
这样就筛出了
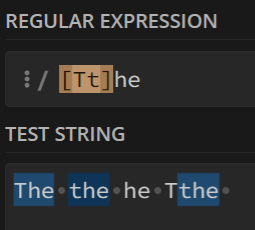
The,the和he可以对比一下不加
?的时候:则是筛选出
The和the
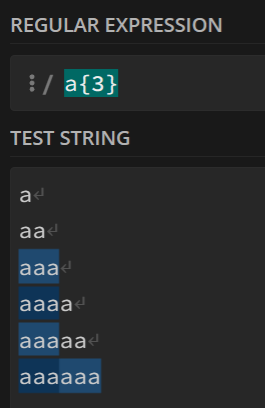
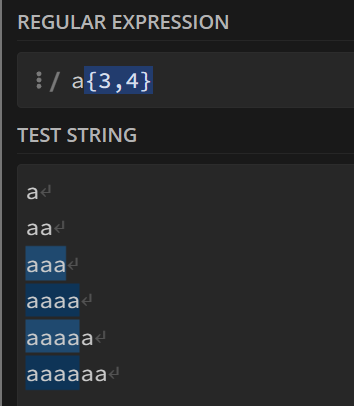
7. {}号
这是一个量词符号,表示某字符出现xxx次时才进行统计
有三种使用情况:(此处以字符a为例)
a{3}意味着将会去统计字符串中的aaa,每出现一次aaa,统计一次。
a{3,}意味着字符a出现≥3次算数

a{3,4}意味着字符a出现3~4次算数
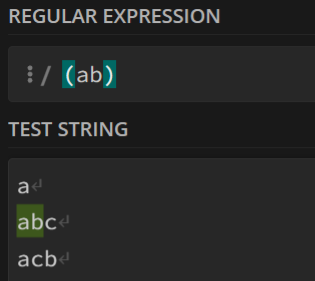
8. ()特征标群
简单来说,就是将括号内的部分看作一个整体。
例如,(ab)就是将两个字符看作一个整体。
比如说,想找出字符串中的所有
ab,则可以这么写:
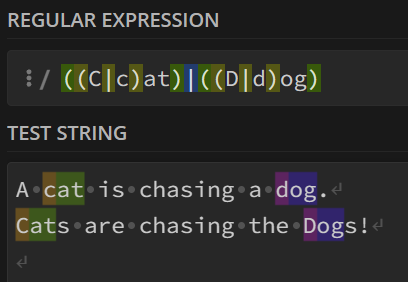
9. |或运算符
与编程语言中的|同义,表示条件的或关系。
例如,想要统计字符串中的
Dog或dog以及Cat或cat,则这样写:
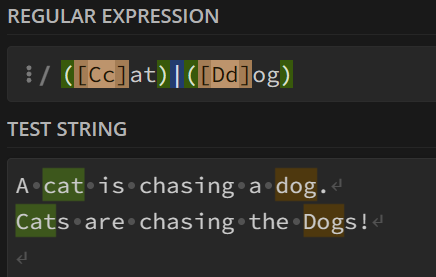
当然,
(C|c)写成[Cc]也是一个效果
10. 锚点^号和$号
若想要指定字符串的开头和结尾,则需要使用锚点。
^开头$结尾
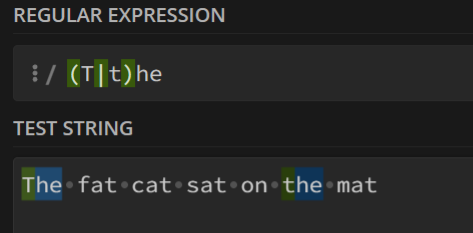
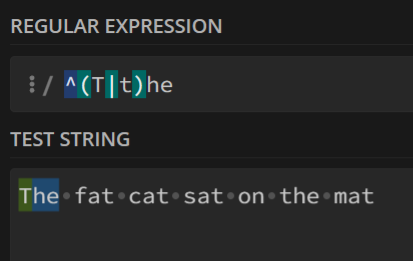
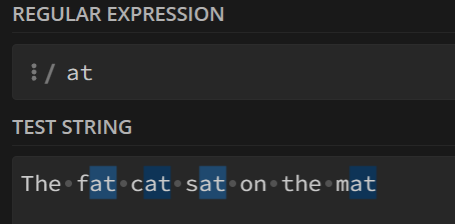
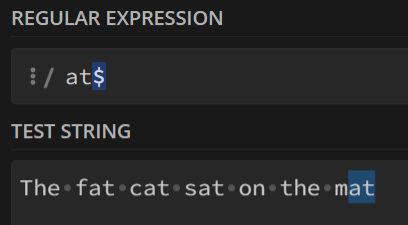
下面以(T|t)he和at匹配字符串The fat cat sat on the mat举例说明:
^c
不加^:
加^:
只匹配了开头的
The,后面的一律不管
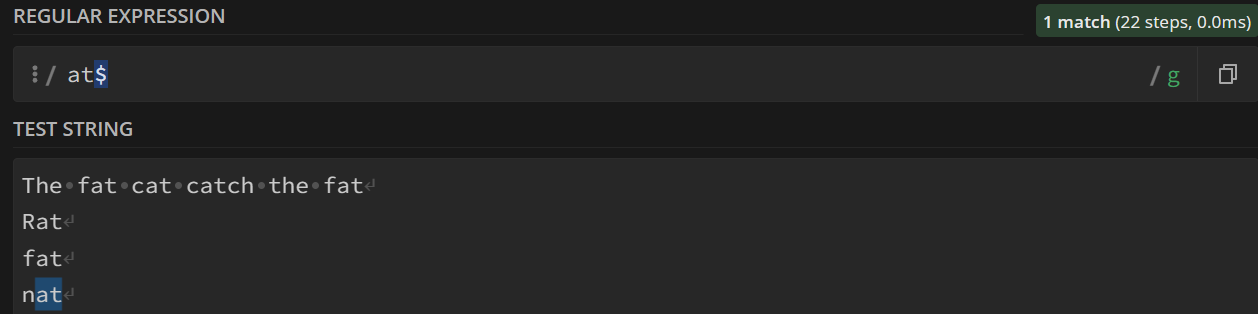
c$
不加$:
加$:
只匹配了结尾的
at,后面的一律不管
三、简写字符集
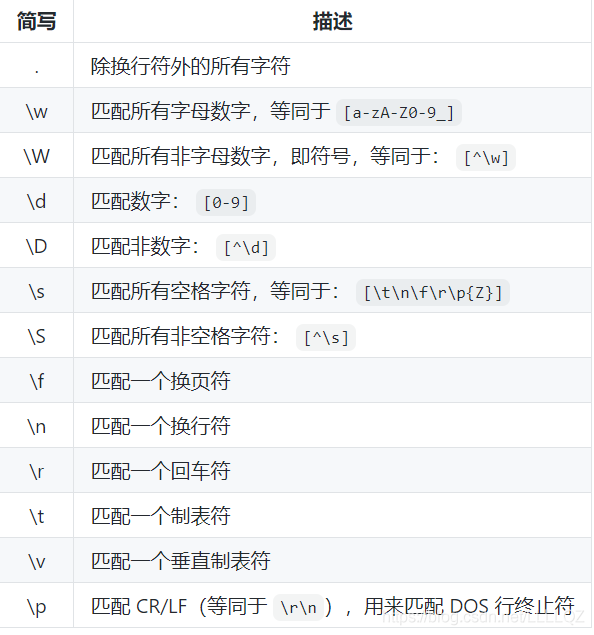
补充:
\b 单词边界,匹配一个单词开始或结束的位置,而不匹配任何实际的字符。
例如,要匹配独立的单词word,则可使用\bword\b,这样遇到sword这样的单词则不会进行匹配
举个例子,我想匹配时间,我可以这样写:
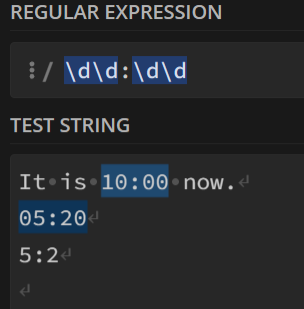
四、零宽度断言
简单来说,与上面所述匹配方式的区别就是,表达式本身只作为约束条件,不再算作匹配结果。
零宽度断言包括先行断言和后发断言,二者用有无<进行区分
其实很好理解,?代表被匹配项,后面是=则代表“应是”,即存在,后面是!则代表“不应是”,即排除。
先行断言用来约束字符串后面的内容
后发断言用来约束字符串前面的内容
具体表示如下:
1. 正先行断言-存在 ?=c
表示第一部分表达式后必须跟着c,才会进行匹配。
例如:
这个表达式就保证了
The后面一定要有fat,这样再会统计。并且fat本身不会作为被统计项。
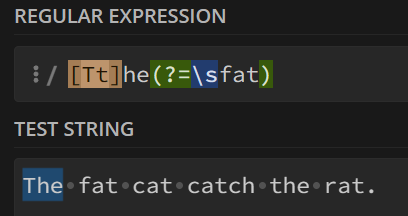
2. 负先行断言-排除 ?!c
和1.正相反,表示其后不能跟着c,才会进行匹配。
例如:
就匹配了后面不跟着fat的the

重要用法:
例如:
使用(?![AEIOU])[A-Z]匹配除元音字母外所有的大写字母
note
用这招,能够实现否定和肯定的相互配合,是很常用的表达式!
3. 正后发断言-存在 ?<=c
表示被匹配字符串前面必须要有c,才会进行匹配
例如:
将前面是the的fat匹配了起来
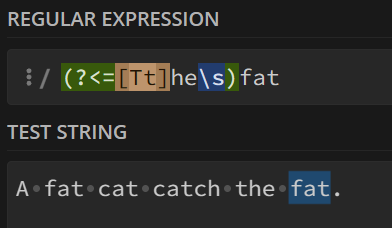
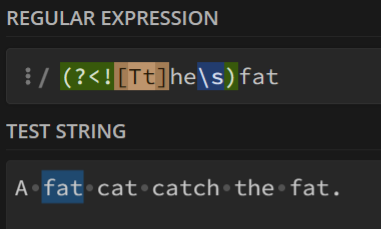
4.负后发断言-排除 ?<!c
与3.相反,代表被匹配项前面不能是c
例如:
将前面不是the的fat匹配了起来
五、标志
标志也叫模式修正符,因为它可以用来修改表达式的搜索结果。 这些标志可以任意的组合使用,它也是整个正则表达式的一部分。
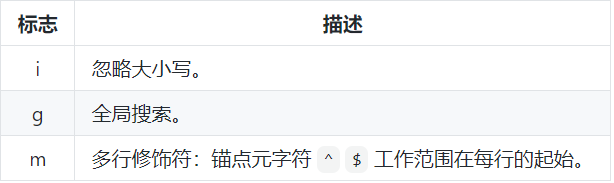
g:global全局
i:insensitive忽略大小写
m:multiple lines逐行匹配
例如表达式
/The/gi就表示统计所有忽略大小写的the
如果不使用/g,则将在第一次匹配成功后终止匹配。
使用/m,意味着表达式会统计每行的结尾,而不只是最后一行的。
不使用
/m:使用
/m:

六、贪婪匹配与惰性匹配
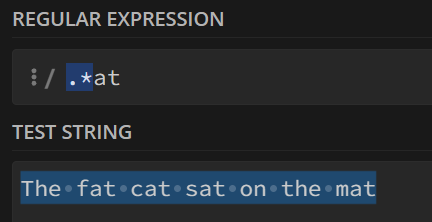
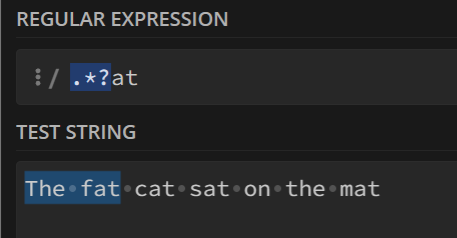
正则表达式默认是贪婪匹配的,使用?可以转换为惰性匹配(不开启全局模式)
例如
.*at会匹配任意结尾是at的字符串,默认贪婪匹配,则会一直匹配直到遇到最后一个at而加上
?转换为惰性匹配,则遇到第一个at就会终止匹配。
到此为止,正则表达式的学习就结束了,快趁热打铁,来练几道题!
练习:
1.
Check if a string contains the word word in it (case insensitive)
- 通过控制单词边界
\b,达到筛选独立单词的目的。 - 通过设置
\i模式,忽略大小写
\bword\b
2.
With regex you can count the number of matches. Can you make it return the number of uppercase consonants (B,C,D,F,..,X,Y,Z) in a given string? E.g.: it should return 3 with the text ABcDeFO!. Note: Only ASCII. We consider Y to be a consonant!
Example: the regex /./g will return 3 when run against the string abc.
题意即提取所有的大写辅音字母。
我们可以通过以下几个方法:
- 直接筛选
[BCDFGHJKLMNPQRSTVWXYZ]
- 反向筛选
(?![AEIOU])[A-Z]